[Python] 함수 정의와 호출: 재사용 가능한 코드 작성법
- Developer/Python
- 2025. 3. 14.
똑같은 코드 몇 번이나 복사-붙여넣기 하고 계신가요? 함수를 사용하면 그런 비효율은 이제 그만.
안녕하세요. 오늘은 코드 중복을 없애고 유지보수를 쉽게 만드는 파이썬 함수에 대해 이야기해보려고 합니다. 처음 프로그래밍을 시작했을 때 저도 함수 없이 코드를 작성했다가 나중에 수정할 때 고생한 기억이 있네요. 이 글에서는 파이썬 함수에 대해서 이것저것 정리할 겸 남겨보려고 합니다.
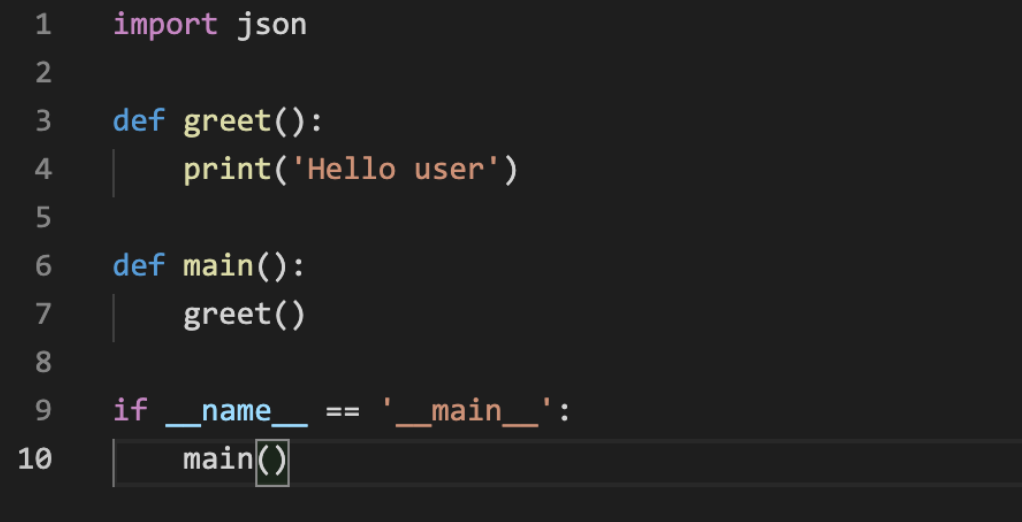
함수의 기본: 정의와 호출
함수는 특정 작업을 수행하는 코드 블록입니다. 매번 같은 코드를 반복해서 작성하는 대신, 함수를 한 번 정의하고 필요할 때마다 호출하면 됩니다. 파이썬에서 함수를 정의하려면 def 키워드를 사용합니다.
함수의 기본 구조는 다음과 같습니다:
def 함수명(매개변수1, 매개변수2, ...):
# 함수 본문
# 실행할 코드
return 반환값 # 선택사항함수를 호출하려면 함수 이름과 괄호를 사용합니다. 괄호 안에는 함수에 전달할 인수(argument)를 넣습니다. 간단한 예제를 살펴보겠습니다:
def greet(name):
"""인사말을 출력하는 함수"""
print(f"안녕하세요, {name}님!")
# 함수 호출
greet("홍길동") # 출력: 안녕하세요, 홍길동님!
greet("김철수") # 출력: 안녕하세요, 김철수님!
위 코드에서 greet는 함수 이름이고, name은 매개변수(parameter)입니다. 함수를 호출할 때 전달하는 "홍길동"과 "김철수"는 인수(argument)라고 합니다.
함수 매개변수와 인자 다루기
파이썬에서는 다양한 방식으로 함수에 데이터를 전달할 수 있습니다. 매개변수(parameter)란 함수 정의에서 사용되는 변수를, 인자(argument)란 함수 호출 시 전달하는 실제 값을 의미합니다. 파이썬은 여러 유형의 매개변수를 지원합니다.
| 매개변수 유형 | 설명 | 예제 |
|---|---|---|
| 필수 매개변수 | 함수 호출 시 반드시 제공해야 하는 매개변수 | def add(x, y): |
| 기본값 매개변수 | 기본값이 지정된 매개변수로, 인자를 생략할 수 있음 | def greet(name="사용자"): |
| 키워드 인자 | 매개변수 이름을 명시하여 전달하는 인자 | add(x=10, y=20) |
| 가변 위치 인자 | 개수가 정해지지 않은 여러 인자를 튜플로 받음 | def sum_all(*args): |
| 가변 키워드 인자 | 개수가 정해지지 않은 키워드 인자를 딕셔너리로 받음 | def config(**kwargs): |
이러한 다양한 매개변수 유형을 활용하면 유연하고 강력한 함수를 작성할 수 있습니다. 예를 들어 봅시다:
def create_profile(name, age, job="학생", **additional_info):
"""사용자 프로필을 생성하는 함수"""
profile = {
"name": name,
"age": age,
"job": job
}
profile.update(additional_info)
return profile
# 함수 호출 예시
profile1 = create_profile("홍길동", 25)
profile2 = create_profile("김철수", 30, "개발자")
profile3 = create_profile("이영희", 28, "디자이너", city="서울", hobby="그림")
print(profile3) # {'name': '이영희', 'age': 28, 'job': '디자이너', 'city': '서울', 'hobby': '그림'}반환값 활용하기
함수는 return 문을 사용하여 결과값을 반환할 수 있습니다. 함수가 명시적으로 값을 반환하지 않으면 None을 반환합니다. 반환값은 함수를 호출한 코드에서 변수에 할당하거나 다른 표현식에서 사용할 수 있습니다.
-
단일 값 반환: 가장 일반적인 형태로, 하나의 값을 반환합니다.
def square(x): return x * x result = square(5) # result = 25 -
다중 값 반환: 쉼표로 구분된 여러 값을 반환할 수 있으며, 이는 튜플로 패킹됩니다.
def get_min_max(numbers): return min(numbers), max(numbers) min_val, max_val = get_min_max([1, 5, 2, 8, 3]) # min_val = 1, max_val = 8 -
조건부 반환: 조건에 따라 다른 값을 반환할 수 있습니다.
def get_grade(score): if score >= 90: return "A" elif score >= 80: return "B" elif score >= 70: return "C" elif score >= 60: return "D" else: return "F" grade = get_grade(85) # grade = "B" -
즉시 종료:
return문은 함수를 즉시 종료합니다. 이는 특정 조건에서 함수 실행을 중단하는 데 유용합니다.def divide(a, b): if b == 0: print("0으로 나눌 수 없습니다.") return None # 함수 종료 return a / b
Q: 함수 이름은 어떻게 짓는 것이 좋을까요?
A: 파이썬에서 함수 이름은 소문자와 밑줄을 사용하는 스네이크 케이스(snake_case)로 작성하는 것이 관례입니다. 함수 이름은 동사나 동사 구문으로 시작하며, 그 함수가 무엇을 하는지 명확하게 설명해야 합니다. 예를 들어, calculate_total, get_user_data, validate_input 같은 이름이 좋습니다. 함수 이름만 보고도 그 용도를 이해할 수 있게 해주세요.
변수 범위와 수명
함수를 다룰 때 변수의 범위(scope)와 수명(lifetime)을 이해하는 것이 중요합니다. 파이썬에서는 변수가 정의된 위치에 따라 접근 가능한 범위가 결정됩니다.
지역 변수와 전역 변수
파이썬에서 함수 내부에서 정의된 변수를 지역 변수(local variable)라고 합니다. 지역 변수는 함수 외부에서 접근할 수 없으며, 함수 실행이 종료되면 메모리에서 제거됩니다.
반면, 함수 외부에서 정의된 변수를 전역 변수(global variable)라고 합니다. 전역 변수는 프로그램의 어디서나 접근할 수 있습니다.
# 전역 변수
message = "안녕하세요"
def greet():
# 지역 변수
name = "홍길동"
print(f"{message}, {name}님!")
greet() # 출력: 안녕하세요, 홍길동님!
# 지역 변수에 접근하려고 하면 에러 발생
# print(name) # NameError: name 'name' is not defined전역 변수 수정하기
함수 내에서 전역 변수를 읽는 것은 가능하지만, 수정하려면 global 키워드를 사용해야 합니다.
counter = 0
def increment():
global counter # 전역 변수 counter를 수정하겠다고 선언
counter += 1
print(f"카운터: {counter}")
increment() # 출력: 카운터: 1
increment() # 출력: 카운터: 2그러나 전역 변수를 과도하게 사용하면 코드가 복잡해지고 디버깅이 어려워질 수 있습니다. 가능하면 함수의 매개변수와 반환값을 통해 데이터를 주고받는 것이 좋습니다.
고급 함수 기능
파이썬에서는 함수를 더 강력하게 활용할 수 있는 다양한 고급 기능을 제공합니다. 이러한 기능을 활용하면 더 유연하고 효율적인 코드를 작성할 수 있습니다.
| 기능 | 설명 | 사용 예시 |
|---|---|---|
| 람다 함수 | 이름 없는 익명 함수로, 간단한 작업에 유용 | lambda x: x**2 |
| 함수 내 함수 | 함수 내부에 중첩된 함수 정의 | def outer(): def inner(): pass |
| 클로저 | 외부 함수의 환경을 기억하는 함수 | def counter(): count=0; def increment(): nonlocal count |
| 데코레이터 | 기존 함수의 기능을 확장하는 패턴 | @my_decorator |
| 제너레이터 | 값을 하나씩 생성하여 메모리 효율성 향상 | def gen(): yield 1 |
람다 함수
람다 함수는 이름 없는 익명 함수로, 한 줄로 간단히 정의할 수 있습니다. 주로 함수를 인자로 전달해야 하는 경우에 유용합니다.
# 일반 함수
def square(x):
return x ** 2
# 동일한 기능의 람다 함수
square_lambda = lambda x: x ** 2
# 람다 함수 활용 예시
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
print(squared) # [1, 4, 9, 16, 25]
# 정렬 시 람다 함수 활용
students = [
{"name": "홍길동", "score": 90},
{"name": "김철수", "score": 85},
{"name": "이영희", "score": 95}
]
students.sort(key=lambda student: student["score"], reverse=True)
print(students) # 점수 기준 내림차순 정렬데코레이터
데코레이터는 기존 함수의 동작을 수정하거나 확장할 수 있는 강력한 도구입니다. 로깅, 성능 측정, 권한 검사 등의 횡단 관심사(cross-cutting concerns)를 처리하는 데 유용합니다.
import time
# 함수 실행 시간을 측정하는 데코레이터
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} 함수 실행 시간: {end_time - start_time:.4f}초")
return result
return wrapper
# 데코레이터 적용
@timer
def slow_function(n):
"""시간이 오래 걸리는 작업을 시뮬레이션하는 함수"""
time.sleep(n) # n초 동안 대기
return n * 2
result = slow_function(1.5) # slow_function 함수 실행 시간: 1.5012초
print(f"결과: {result}") # 결과: 3.0함수 작성 모범 사례
효과적인 함수를 작성하려면 몇 가지 모범 사례를 따르는 것이 좋습니다. 이러한 관행을 따르면 코드의 가독성, 유지보수성, 재사용성이 향상됩니다.
- 한 가지 작업만 수행하도록 설계하기: 함수는 단일 책임 원칙(Single Responsibility Principle)을 따라야 합니다. 한 함수가 여러 작업을 수행하면 디버깅과 테스트가 어려워집니다.
-
명확한 이름 사용하기: 함수 이름은 그 기능을 명확하게 설명해야 합니다.
process_data()보다는calculate_average_salary()와 같이 구체적인 이름이 좋습니다. - 적절한 길이 유지하기: 함수가 너무 길면 이해하기 어렵습니다. 일반적으로 함수는 화면 하나에 들어갈 수 있을 정도의 길이가 적당합니다.
- 문서화하기: 독스트링(docstring)을 사용하여 함수의 목적, 매개변수, 반환값 등을 문서화하세요. 이는 다른 사람이 코드를 이해하는 데 도움이 됩니다.
- 기본값 매개변수 활용하기: 자주 사용되는 기본값을 설정하면 함수 호출이 간결해집니다.
- 전역 변수 사용 최소화하기: 가능하면 함수 매개변수와 반환값을 통해 데이터를 주고받으세요.
- 입력 검증하기: 함수 시작 부분에서 입력값을 검증하여 오류를 빠르게 발견하세요.
- 반환값 일관성 유지하기: 함수는 항상 동일한 유형의 값을 반환해야 합니다.
# 잘 작성된 함수의 예시
def calculate_discount(price, discount_rate=0.1):
"""
상품 가격에 할인율을 적용하여 할인된 가격을 계산합니다.
Args:
price (float): 상품의 원래 가격
discount_rate (float, optional): 할인율 (0.0 ~ 1.0). 기본값은 0.1 (10%)
Returns:
float: 할인된 가격
Raises:
ValueError: price가 음수이거나 discount_rate가 0~1 범위를 벗어날 경우
"""
# 입력값 검증
if price < 0:
raise ValueError("가격은 0 이상이어야 합니다.")
if not 0 <= discount_rate <= 1:
raise ValueError("할인율은 0과 1 사이여야 합니다.")
# 할인 계산
discount_amount = price * discount_rate
discounted_price = price - discount_amount
return discounted_price
Q: 함수에서 발생하는 오류를 어떻게 효과적으로 디버깅할 수 있나요?
A: 함수 디버깅을 위한 몇 가지 효과적인 방법이 있습니다. 첫째, print 문을 전략적으로 배치하여 중간 값을 확인하세요. 둘째, 복잡한 함수는 작은 부분으로 나누어 각 부분을 개별적으로 테스트하세요. 셋째, Python의 pdb 모듈을 사용하여 대화형 디버깅을 수행할 수 있습니다(import pdb; pdb.set_trace()). 넷째, 함수에 입력값의 경계 조건(예: 빈 리스트, 0, 음수 등)을 테스트하여 견고성을 확인하세요. 마지막으로, 오류 메시지를 주의 깊게 읽고 오류가 발생한 정확한 위치를 파악하는 것이 중요합니다.
Q: 파이썬 함수의 성능을 개선하는 방법이 있을까요?
A: 파이썬 함수의 성능을 최적화하는 몇 가지 방법이 있습니다. 먼저, 반복문 내에서 함수 호출을 최소화하세요. 루프 바깥에서 계산할 수 있는 값은 미리 계산해 두는 것이 좋습니다. 데이터 구조를 적절히 선택하는 것도 중요합니다. 예를 들어, 요소 존재 여부를 자주 확인해야 한다면 리스트보다 집합(set)이 효율적입니다. 자주 호출되는 계산 집약적 함수는 메모이제이션(memoization)을 활용하여 이미 계산된 결과를 캐싱하세요. 큰 데이터셋을 다룰 때는 리스트 컴프리헨션이나 제너레이터를 활용하면 메모리 효율성이 향상됩니다. 마지막으로, 정말 성능이 중요한 부분은 NumPy 같은 최적화된 라이브러리를 활용하거나 필요하다면 C 확장을 고려해볼 수 있습니다.
실용적인 함수 예제: 데이터 분석 도우미
아래 코드는 데이터 분석 작업에서 유용하게 사용할 수 있는 함수들의 모음입니다. 이 예제에서는 함수 정의, 매개변수 처리, 반환값, 함수 문서화 등 지금까지 배운 개념들을 실제로 적용해 보겠습니다.
"""데이터 분석을 위한 유틸리티 함수 모음"""
def clean_data(data, columns=None, drop_na=True, fill_value=None):
"""
데이터 전처리 작업을 수행하는 함수
Args:
data (list of dict): 정리할 데이터 목록
columns (list, optional): 유지할 열 이름 목록. None이면 모든 열 유지.
drop_na (bool, optional): True면 NA 값이 있는 행 제거, 기본값 True
fill_value (any, optional): NA 값을 채울 값. drop_na가 False일 때만 사용.
Returns:
list of dict: 정리된 데이터 목록
"""
# 결과를 저장할 빈 리스트
cleaned_data = []
for item in data:
# 지정된 열만 선택
if columns:
filtered_item = {k: item.get(k) for k in columns if k in item}
else:
filtered_item = item.copy()
# NA 값 처리
has_na = any(v is None for v in filtered_item.values())
if has_na:
if drop_na:
continue # NA가 있는 행 건너뛰기
elif fill_value is not None:
# NA 값을 지정된 값으로 채우기
for k in filtered_item:
if filtered_item[k] is None:
filtered_item[k] = fill_value
cleaned_data.append(filtered_item)
return cleaned_data
def calculate_statistics(data, numeric_columns):
"""
주어진 데이터의 수치형 열에 대한 기본 통계를 계산하는 함수
Args:
data (list of dict): 통계를 계산할 데이터
numeric_columns (list): 수치형 데이터가 포함된 열 이름 목록
Returns:
dict: 각 열에 대한 통계 정보
"""
stats = {}
for column in numeric_columns:
# 해당 열의 모든 값 추출
values = [item[column] for item in data if column in item and item[column] is not None]
if not values:
stats[column] = {"error": "No valid data"}
continue
# 기본 통계 계산
count = len(values)
total = sum(values)
mean = total / count
minimum = min(values)
maximum = max(values)
# 중앙값 계산
sorted_values = sorted(values)
mid = count // 2
median = sorted_values[mid] if count % 2 == 1 else (sorted_values[mid-1] + sorted_values[mid]) / 2
# 통계 정보 저장
stats[column] = {
"count": count,
"mean": mean,
"median": median,
"min": minimum,
"max": maximum,
"range": maximum - minimum
}
return stats
def group_by(data, group_column, agg_column=None, agg_func=None):
"""
데이터를 그룹화하고 집계하는 함수
Args:
data (list of dict): 그룹화할 데이터
group_column (str): 그룹화할 기준 열
agg_column (str, optional): 집계할 열. None이면 그룹별 개수만 반환.
agg_func (callable, optional): 집계 함수. None이면 목록 반환.
Returns:
dict: 그룹별 집계 결과
"""
groups = {}
for item in data:
if group_column not in item:
continue
group_key = item[group_column]
# 그룹 딕셔너리에 키가 없으면 초기화
if group_key not in groups:
groups[group_key] = []
# 집계할 열이 있으면 해당 값만 추가, 없으면 전체 항목 추가
if agg_column and agg_column in item:
groups[group_key].append(item[agg_column])
else:
groups[group_key].append(item)
# 집계 함수가 제공되면 적용
if agg_func and agg_column:
for key in groups:
groups[key] = agg_func(groups[key])
return groups
# 사용 예시
if __name__ == "__main__":
# 샘플 데이터
sample_data = [
{"id": 1, "name": "Alice", "age": 30, "salary": 5000, "department": "HR"},
{"id": 2, "name": "Bob", "age": 25, "salary": 6000, "department": "IT"},
{"id": 3, "name": "Charlie", "age": 35, "salary": 7500, "department": "IT"},
{"id": 4, "name": "David", "age": None, "salary": 4500, "department": "HR"},
{"id": 5, "name": "Eve", "age": 28, "salary": None, "department": "Marketing"}
]
# 데이터 정리
print("=== 데이터 정리 ===")
cleaned = clean_data(
sample_data,
columns=["name", "age", "department"],
drop_na=False,
fill_value=0
)
print(cleaned)
# 통계 계산
print("\n=== 통계 계산 ===")
stats = calculate_statistics(sample_data, ["age", "salary"])
print(stats)
# 그룹화
print("\n=== 부서별 급여 평균 ===")
grouped = group_by(sample_data, "department", "salary", lambda x: sum(filter(None, x)) / len([i for i in x if i is not None]) if any(i is not None for i in x) else 0)
print(grouped)
이 코드 예제는 실제 데이터 분석 작업에서 자주 필요한 기능들을 함수로 구현한 것입니다. clean_data 함수는 데이터 전처리를, calculate_statistics 함수는 기본 통계 계산을, group_by 함수는 데이터 그룹화 및 집계를 담당합니다.
각 함수는 특정 작업에 집중하면서도 매개변수를 통해 유연성을 제공합니다. 예를 들어 clean_data 함수에서는 결측값을 제거하거나 특정 값으로 채울지 선택할 수 있고, group_by 함수에서는 사용자 정의 집계 함수를 전달할 수 있습니다.
이 모듈은 데이터 처리 파이프라인을 구축하는 데 사용할 수 있습니다. 예를 들어, 원시 데이터를 먼저 clean_data로 정리한 다음, calculate_statistics로 통계를 구하고, group_by로 필요한 인사이트를 도출하는 흐름으로 사용할 수 있습니다.
함수형 프로그래밍 스타일 활용하기
파이썬은 함수형 프로그래밍 스타일도 지원합니다. 함수형 프로그래밍은 데이터 변환과 처리를 중심으로 하는 패러다임으로, 특히 데이터 처리 파이프라인을 구축할 때 유용합니다. 다음은 함수형 스타일로 작성된 예제입니다.
from functools import reduce
def pipeline(*funcs):
"""
함수들을 순차적으로 실행하는 파이프라인을 생성하는 함수
Args:
*funcs: 순차적으로 실행할 함수들
Returns:
callable: 파이프라인 함수
"""
def pipe(data):
return reduce(lambda result, func: func(result), funcs, data)
return pipe
# 데이터 변환 함수들
def filter_adults(people):
"""성인만 필터링하는 함수"""
return [person for person in people if person.get('age', 0) >= 18]
def extract_names(people):
"""사람들의 이름만 추출하는 함수"""
return [person.get('name', '') for person in people]
def format_names(names):
"""이름을 대문자로 변환하는 함수"""
return [name.upper() for name in names]
# 파이프라인 생성
process_people = pipeline(
filter_adults,
extract_names,
format_names
)
# 테스트 데이터
people = [
{'name': 'Alice', 'age': 25},
{'name': 'Bob', 'age': 17},
{'name': 'Charlie', 'age': 30},
{'name': 'David', 'age': 15}
]
# 파이프라인 실행
result = process_people(people)
print(result) # ['ALICE', 'CHARLIE']
이 예제에서는 pipeline 함수를 정의하여 여러 함수를 순차적으로 실행하는 파이프라인을 만들었습니다. 이러한 접근 방식은 코드를 모듈화하고 재사용성을 높이는 데 도움이 됩니다. 각 함수는 한 가지 변환에만 집중하므로 테스트와 디버깅이 용이하며, 필요에 따라 파이프라인을 쉽게 재구성할 수 있습니다.
함수형 프로그래밍 스타일은 특히 데이터 처리, 병렬 처리, 이벤트 기반 프로그래밍 등에서 강점을 발휘합니다. 파이썬의 map, filter, reduce 함수와 함께 사용하면 더욱 강력한 데이터 처리 파이프라인을 구축할 수 있습니다.
마무리
지금까지 파이썬 함수의 기본 개념부터 고급 기능까지 살펴보았습니다. 잘 작성된 함수는 코드의 재사용성, 가독성, 유지보수성을 크게 향상시키는 열쇠입니다. 함수를 적절하게 활용하면 중복 코드를 제거하고, 모듈화된 설계로 복잡한 문제를 더 작고 관리하기 쉬운 부분으로 나눌 수 있습니다.
함수를 작성할 때는 단일 책임 원칙을 기억하세요. 각 함수는 한 가지 작업만 수행하고, 그 작업을 잘 수행해야 합니다. 또한 함수 이름과 매개변수 이름을 명확하게 지정하고, 문서화를 통해 다른 개발자들이 쉽게 이해하고 사용할 수 있게 해주세요.
처음에는 함수를 적절히 설계하고 작성하는 것이 시간이 더 걸리는 것처럼 느껴질 수 있습니다. 하지만 장기적으로 봤을 때, 잘 작성된 함수는 디버깅 시간을 줄이고, 코드 재사용을 촉진하며, 팀 협업을 원활하게 하는 등 여러 이점을 제공합니다.
특히 대규모 프로젝트나 오래 유지보수해야 하는 코드베이스에서는 함수의 중요성이 더욱 두드러집니다. 코드를 처음부터 함수 단위로 설계하고, 각 함수가 명확한 목적을 가지도록 구성하면, 나중에 코드를 확장하거나 수정할 때 훨씬 수월해질 것입니다.
이제 여러분은 파이썬 함수의 다양한 측면을 이해하고, 이를 효과적으로 활용할 준비가 되었습니다. 자신만의 함수 라이브러리를 구축하고, 코드의 질을 향상시키는 여정을 시작해보세요. 좋은 함수를 작성하는 능력은 프로그래머로서 가장 가치 있는 기술 중 하나임을 기억하세요.
'Developer > Python' 카테고리의 다른 글
| [Python] input() 함수로 사용자와 상호작용하기 (0) | 2025.03.14 |
|---|---|
| [Python] 구구단 출력 프로그램 만들기 (0) | 2025.03.14 |
| [파이썬] 리스트, 튜플, 딕셔너리 (0) | 2025.03.14 |
| [파이썬] for문과 while문으로 반복 작업 자동화하기 (0) | 2025.03.13 |
| [파이썬] 조건문(if-else)으로 만드는 나만의 퀴즈 프로그램 (0) | 2025.03.12 |